






After the commercialization of relational databases in the 1980s, there has been exponential growth in the data. Companies like Oracle made them very popular. This further evolved into big data. According to Statista, the data consumed worldwide in 2022 is to the tune of 97 zettabytes. As organizations grew so did their data size as well as the demand for it. They wanted to analyze the data, build reports, and take data-driven decisions. For this, they needed historical and integrated data. But the data was in their OLTP systems.
- OLTP systems cannot handle large data volumes, hence they can’t store the data indefinitely.
- The operational OLTP systems have fragmented data in multiple systems.

The data warehouse concept was born, capable of both, storing indefinitely and integrating data from multiple data sources. However, the data cannot magically appear in a data warehouse and organize itself. You need to build data pipelines that would extract, transform, and load data in the warehouse of data. Thus emerged the concept of ETL (Extract, Transform, and Load) processes.
Data Pipeline Testing
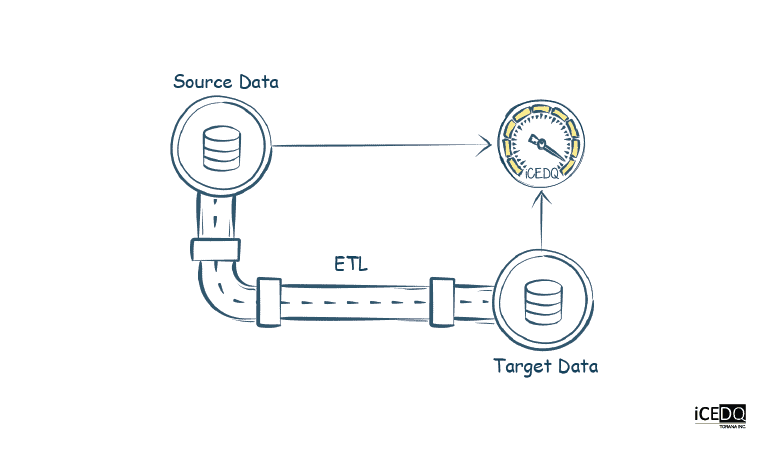

Since the early 2000’s ETL developers started churning out these ETL processes using various languages and ETL tools such as Java, SQL, and Python. However, the data projects started failing or being delayed at an alarming rate of 85%.
- Lack of data testing: Anything that is developed must be tested. But the data developers lacked the discipline of testing or QA. Also, the management was never interested in non-glamorous activities such as testing. It will be surprising to know that many ETL processes are never tested until they go into production.
- Lack of Automated ETL testing tools such as iCEDQ. Data Pipeline testing is essentially different from application testing. While in application testing, there are UI and testing tools such as selenium that replay the user actions. ETL is background processes there is no UI. Designing QA software was difficult.
- Additionally, the output generated by the ETL process is totally dependent on the input data that is provided to it. Every time the data pipeline is run it might use different data to process so hard coding of some scripts is almost impossible.
This meant, either no testing or some halfhearted manual ETL testing. Humans have a limitation in processing or inspecting hundreds to a few thousand records. Imagine a world where there are billions of records and testing is done on less than .001% of the total.
Putting untested or poorly tested processes in production directly creates unimaginable damage to enterprises.
- The data project is delayed or recalled because of data issues.
- Cost overruns because of delays and constant fixes.
- Fixing data issues in production issues extremely expensive.
- It directly affects the reputation of both the delivery team and the company.
- There are regulatory compliance issues that can result in criminal liabilities.
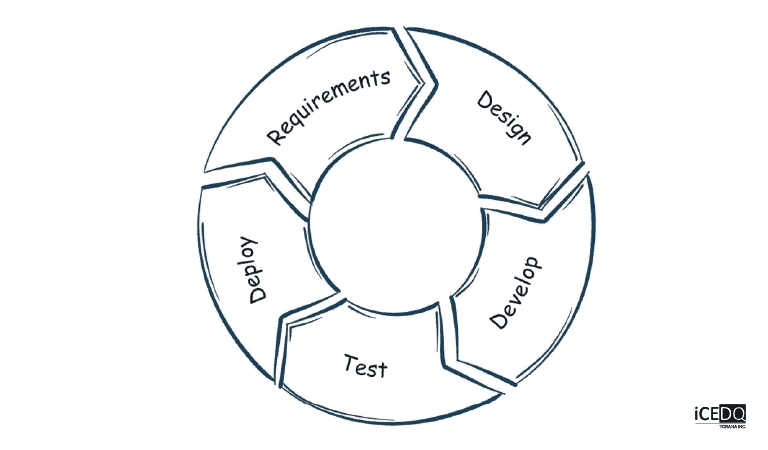

The SDLC cycle of any project involves testing. There is no good reason for organizations to ignore data pipeline testing since automated ETL testing tools are readily available. There is little downside in adopting data pipeline testing and a lot to gain.

