






ETL became popular in the 1970s when companies began working with mainframes to store transaction data for all their operations. Lastly, there was a need to provide complex and accurate data integration. This is when the ETL system helped the companies.
Data warehouses which were created in the 1980s did not help a lot. And that reality showed that varied databases demand special ETL tools. Therefore, companies have chosen different ETL tools for use in different data warehouses. However, these early solutions required special tech-savviness. They also had to be adjusted frequently for different data sources. The increase in the volume and complexity of the data structure has led to the automated enhancement of ETL work. It excludes manual coding and offers an automated process for monitoring data flows. Now, let’s find out how a perfect elt data integration solution looks!
Scope of ETL tools
Over the past few years, the trend in the use of ETL tools has been substantial. Initially, ETL processes were only performed manually when data analysts were hired to integrate the data. Yet, with the advent of no-code tools from powerful software companies, ETL tools began to play a significant role. The no-code market is expected to grow and reach $20+ billion by the beginning of 2023. Thus, these no-code ETL tools occupy a weighty market share.
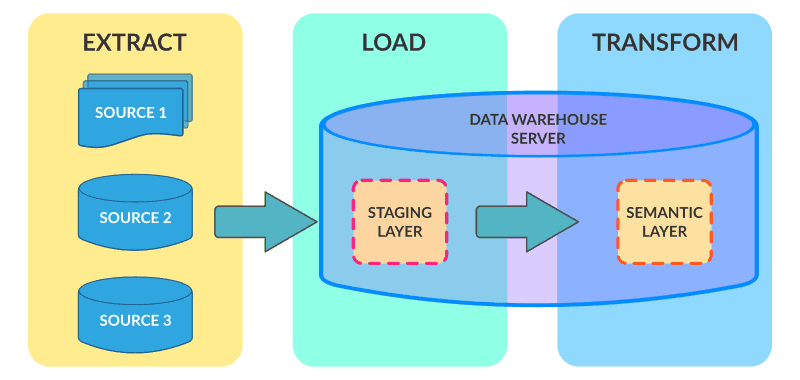

How does the manual ETL work?
Manual ETL performance requires data science and architecture analysts. There are no visual code-free operations and the help of a developer is highly needed. This additional time is required not only as a one-time effort but every time for all data sources, which increases the total amount of work. In addition, more work hours for data engineers means higher costs for you.
Developers create pipelines in the process of manual data extraction, conversion, and loading. The larger the range of data and data warehouses, the more time and human resources are required. Similarly, the data integration process requires more coding to start it.
In general, the following are the main processes to be performed when manually integrating data:
- Documenting the requirement and describing the whole process is the first step.
- Development of data integration models and data warehouses for all databases from which information needs to be extracted.
- Pipeline coding for each data source that links the whole data set to the data warehouse.
- Rerunning the whole process to make sure everything is perfect.
- The sub-step for each task is different for all data streams because of their nature and data format. This makes the process complex and lengthy.
That’s why it is easier to find an ELT data integration tool, like the one from Visual Flow. It could be the no-coding drag-n-drop solution you have been looking for.
How does a drag-and-drop ELT data integration solution work?
Working with no-code ETL processes, you will encounter many scenarios in which ETL tools will be useful.
They include:
- Connectors
If you have different data conveyors, you can easily connect them without adding a line of code. For example, if your client’s data is stored in Oracle and the order information is stored in Microsoft Excel, the tool will connect to these data stores.
- Data profiling
You have to identify the data to make the most of it. Based on certain values the data will be automatically sorted.
- Turnkey
The ETL program can provide ready-made transformations that can be directly applied to the source data, which greatly simplifies the work.
- Convenient planning
You can schedule an ETL pipeline with specific triggers so that everything remains automated and you don’t have to make any overt efforts at a certain time.
Is there some difference between code ETL and drag-n-drop ETL?
The manual execution of ETL processes and the use of no-code ETL tools are very different. The latter is undoubtedly a complex and complex process. This section highlights other areas where manual coding is different from the use of tools:
Usage
No-code ETL tools already have an established process of extracting unstructured data, performing the conversion process, and downloading them into a clean repository. So you don’t have to do anything special except specify the locations for the data conveyors.
However, manual execution of the process is difficult, even for experienced data experts, because it takes a long time to obtain valuable information from the data. In addition, there is the possibility of an error in the coding, which could spoil the whole process of data integration.
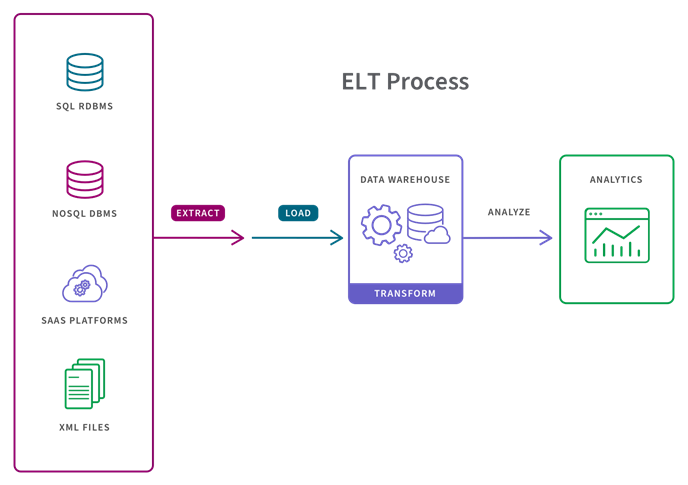

Maintenance
Maintenance of manual ETL code is a difficult task. You will have to master several computer languages to well control the whole process. There are also many data integration scenarios for which you may need to perform this process. Thus, the process will have to be modified for each new type of information required. Luckily, this will not be a problem for your organization if you choose ETL solutions by Visual Flow.
Value
In terms of cost, no-code ETL solutions are the best option, because the use of these tools presupposes a predefined subscription cost, which is not so expensive given the value you get in return. But hiring a data analyst will require a lot of investment. Since the developer’s annual reward is over $100,000, you will also have to invest in other employees who may not be experts, but need to know the ETL processes to help the data analyst. In addition, you will need specialized equipment that will further increase your costs.
Conclusion
To get meaningful information that supports your company’s growth, you need to combine all data from several disparate sources in a convenient format. Here you can help the ETL system.
ETL simplifies and extends the extraction of raw data, dispersed across multiple systems, into the data warehouse. That’s why, opting for the right ETL tool is as necessary, as you can only imagine. For example, a chosen ETL tool has access to all data sources used by your business. It should offer an error-free user interface and provide consistent, accurate, and secure data loading.

